In today’s world, the success of any company depends on how well it utilizes its data be it while providing services to other businesses or directly offering its customers. Taking cues from the same, this blog is an in-depth view of data lake vs data warehouse.
Before knowing what are the major differences between Data Lake vs Data Warehouse, the blog would touch upon what is a data lake, its concepts, architecture, and benefits. In the same way, the blog would talk about the meaning of what is a data warehouse, its concepts, data warehouse architecture, and benefits of the data warehouse. Let us look at the same.
History Of Data Lake And Data Warehouse
- In the initial leg of the 1990s, data was still in the process of gaining prominence and huge amounts of stored data were beginning to be considered an asset for multinationals.
- This led to an increase in the demand for the data warehouse where companies could store different types of data that could assist them in their marketing activities and analysis.
- As the technological world developed further, James Dixon came up with the concept of the data lake. The coming of the data lake marked a shift in data technology from old methods.
- Big Companies use data warehouses to effectively store and manage structured data. The data stored could then be operated using the schema-on-write model.
- In this tussle of data lake vs data warehouse, businesses have to come up with an inclusive Data and analytics Strategy that has components of both- data lake and data warehouse.
- One of the recent trends going around is that companies are incorporating data lakes into their systems along with data warehouses. For instance, it is seen how AB InBev has data lakes set up for large-scale storage. Another example is that of Epic Games which uses a data lake and data warehouse to monitor and manage workflows on AWS.
What is a Data Lake?
To answer what is a data lake is that it stores data that is structured, semi-structured, and unstructured and operates within a schema-on-read model. Data Lake requires the assistance of data scientists for drawing useful outcomes out of multiple structure data sets.
It offers a more flexible option for combining different data with less cost and time. A data lake example is Google Cloud Storage. If we talk about another example of a data lake it will be Amazon S3.
What is the Data Lake Concept
The data lake concept comprises all nine components. They include all from data governance to ingestion to data discovery to lineage and exploration.
1. Data Ingestion
Data ingestion allows users to collect data from different sources and load it into a single data lake. The different types of data ingestion include real-time, batch, and one-time load.
2. Data Storage
Data lake offers scalable and cost-effective storage and it supports various data formats. In addition to this, data lakes enable fast access to data exploration.
3. Data Governance
As the word itself describes, data governance includes monitoring, integration, and accessibility of data. The governance part includes ensuring the security of data stored in the data lake.
4. Data Security
Data security is an important aspect of a data lake as it prevents unauthorized users to access the company data. The important features of data lake security are authentication, accounting, authorization, and data protection.
5. Data Quality
Data quality is another defining feature of a data lake and offers companies to prevent drawing poor quality insights leading to miscalculated outcomes.
6. Data Discovery
In the data discovery, the stage tagging technique is utilized to understand and monitor the data while it is stored in the data lake. This stage is before the stage where data is prepared for analysis.
7. Data Auditing
Data Auditing includes monitoring changes to the key datasets. Data Auditing keeps a record of all the changes done to the data including when and who implemented them.
8. Data Lineage
Data Lineage tracks the movements of data over a specific period. Also, data lineage helps users get rid of errors during the process from source to destination.
9. Data Exploration
Data Exploration is the last data lake concept. It is the stage just before analyzing data. This helps to identify the suitable dataset needed for analysis and insights.
What is Data Lake Architecture
Data lake architecture comprises of ingestion tier, insights tier, HDFS, distillation tier, processing tier, and unified operations tier.
(Source: https://www.guru99.com/data-lake-architecture.html)
1. Ingestion Tier
The ingestion tier is on the left side and it reflects the data sources. In the ingestion tier, the data is uploaded in two ways- firstly in real-time, and secondly in the form of batches.
2. Insights Tier
The insight tier contains the research including the observations drawn from the given data. For data analysis, tools like SQL queries, NoSQL, and Excel are used.
In usual circumstances, the insight is on the right side.
3. HDFS
HDFS is a solution used for both structured and unstructured data and is offered at a lower cost. It acts as a landing zone for all data stored in the system.
4. Distillation Tier
The distillation tier collects data from the storage tier, it could be either structured or unstructured data. Then, the unstructured data is converted into structured data for drawing insights.
5. Processing Tier
The processing tier takes into account interactive data and analyzes queries in the form of batches leading to structured data for drawing easier insights.
The processing tier uses mathematical equations, analytical algorithms, and user queries depending on the time.
6. Unified Operations Tier
The last tier of data lake architecture is the unified operations tier governs and monitors the management system. It includes management of data, monitoring workflows, and auditing and proficiency management.
Benefits of Data Lake
1. Storage of Structured or Unstructured Data
One of the major benefits of the data lake is that it allows users to store large volumes of unstructured data. Companies can use end-to-end self-service tools that allow them to access a wide range of data.
Self-service tools help companies to access unstructured data in less time.
2. Easy Accessibility of Data and Quicker Insights.
The other benefit of a data lake is that it allows companies to store data in a structured format. Data in a structured format would help companies to readily use them as compared to data kept in raw forms.
Structured data empowers companies and data scientists to discover new methods of analyzing data and gain new valuable insights.
What is a Data Warehouse?
A data warehouse is a database designed for storing large amounts of unstructured and raw data is the most simple and easy definition to understand what is a data warehouse.
Once the data is collected from all departments for data analysts and data scientists to analyze, it is kept in a single repository called a data warehouse.
Departments from which data is collected include customer care, marketing, sales, and financial team. Data warehouse example is Google BigQuery, Amazon Redshift, and Oracle.
Data Warehouse Concept
Data warehouse concepts comprise Kimball and Inmon. This segment is going to deal with these two concepts in good detail.
1. Kimball
Kimball’s approach begins with identifying business processes and queries that the data warehouse answers. Then, the sets of information are analyzed and documented accordingly. The Extract Transform Load (ETL) software collects data from all data sources called data marts.
Then that data is accumulated at a commonplace called staging. Following staging, data is transformed into an OLAP cube.
2. Inmon
The other data warehouse concept is Inmon which begins with the corporate data model. Inmon defines key areas and monitors aspects like customer, product, and vendor.
The Inmon model offers brands a detailed logical model that is useful for major operations. Following the details, the model is further developed physically.
Data Warehouse Architecture
Data warehouse architecture is divided into three tiers one-tier architecture, two-tier architecture, and three-tier architecture.
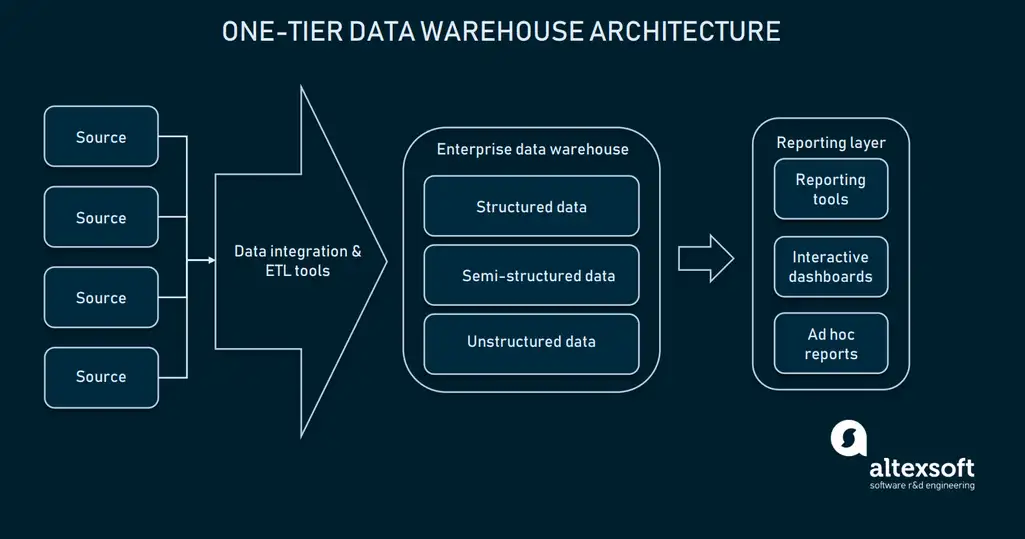
1. One-Tier Architecture
(Source: https://www.altexsoft.com/blog/enterprise-data-warehouse-concepts/)
Usually, the data warehouse is a relational database with specific modules that allow multidimensional data or segregated information that allows for easier access. One-tier architecture is the oldest warehousing form that allows for configured data integration.
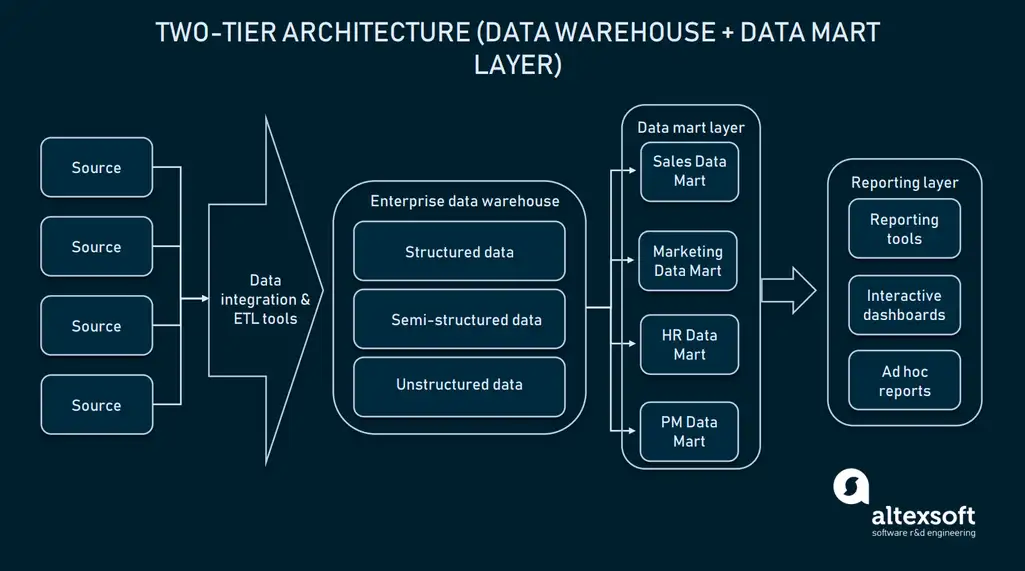
2. Two-Tier Architecture
(Source: https://www.altexsoft.com/blog/enterprise-data-warehouse-concepts/)
In two-tier architecture, an extra layer called a data mart is added between the user interface and EDW. A data mart is a low-key storage and it consists of information that belongs to a particular domain.
Thus, a data mart is a small-sized database that allows EDW to store specific information related to the sales, operations, or marketing department, etc.
3. Three-Tier Architecture
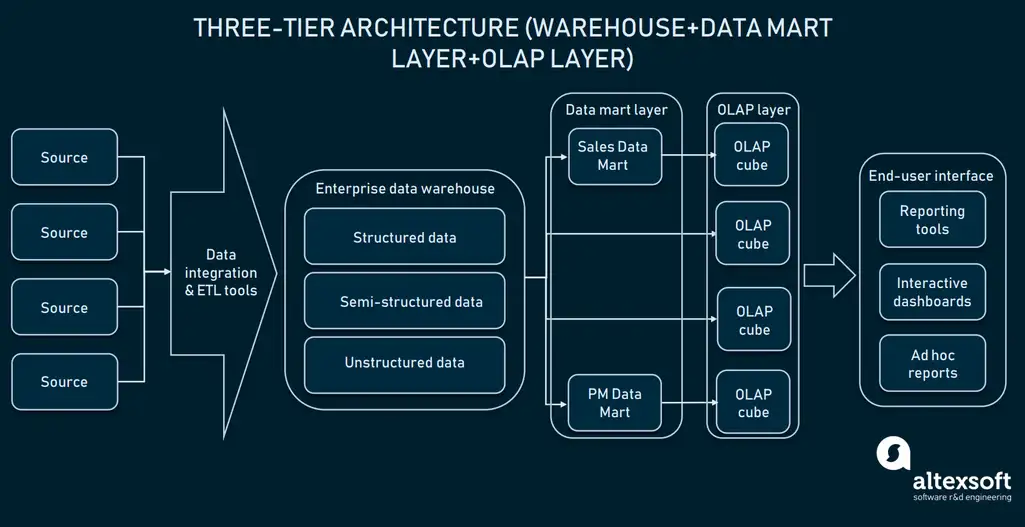
(Source: https://www.altexsoft.com/blog/enterprise-data-warehouse-concepts/)
In the three-tier architecture, another layer of OLAP cubes is added over the data mart layer. An OLAP cube contains a specific type of database although it is representative of all data dimensions.
Relational databases represent data in only two dimensions that is Excel or Google Sheets. However, OLAP allows businesses to collect and integrate data from multiple dimensions.
Benefits of Data Warehouse
1. Serves as a “Single Source Of Truth”
One of the major benefits of a data warehouse is that it offers a “single source of truth”. Following the initial work of monitoring, processing, and cleansing data, the warehouse serves as a consistent repository. This source is extremely helpful for drawing useful insights, business data analysis, and creative collaboration.
2. Quicker Insights
One of the other benefits of a data warehouse is that it helps brands get quicker insights. A data warehouse is useful in managing and monitoring unstructured data.
In this way, it is comprehensible for business analysts and users to access and analyze complex data. This ensures data is readily available and upholds the accuracy of data. This helps businesses to draw new insights.
6 Key Differences Between a Data Lake And Data Warehouse
This section is an overview of data lake vs data warehouse. The following points range from accessibility of data to its storage in native format to schema on reading.
1. Flexible Accessibility Of Data
The first difference between a data warehouse and a data lake is that data scientists, engineers, and analysts can access data quickly and easily. This is easier when compared to traditional BI architecture.
The use of data lakes enhances agility and leads to added opportunities for data exploration. In addition to that, the data lakes offer proof of concept activities and business intelligence services that are shaped by users themselves within the given boundaries of privacy.
Data warehouse, on the other hand, stores structured and processed data which is why it is harder to manipulate than data lakes.
2. The Difference In Purposes of a data warehouse and a data lake
The other difference lies in the purpose of data lakes and data warehouses. The purpose of data lakes changes according to the case in question.
Data lake purpose constitutes data discovery, user profiling, and machine learning. On the other hand, a data warehouse is utilized for visualizations, reporting, and business intelligence.
3. Segregated Storage And Compute Systems Of Data Lake vs Integrated System Of Data Warehouse
If the storage and computing are separated, the data lake offers companies to optimize their costs by allocating storage requirements according to frequency. Further, the separation provides businesses to archive unstructured data.
This allows businesses to run analyses and experiments using new technologies. On the contrary, data warehouses and ETL systems are strictly integrated, for instance- compute had to be expanded to increase storage capacity and vice versa.
4. Different Storage Formats
Another difference between these two is that the data stored in the data lake is in a raw form. However, data stored in the data warehouse is in a processed form, meaning that data is ready to be used by the team.
Since, a data lake stores raw and unprocessed data, there is always a risk of data converting into data swamps. As a consequence, a data lake requires more storage capacity and a data warehouse.
5. Cost-Effectiveness
A data lake stores unprocessed data and does not follow a particular structure. This is the primary reason why data lakes are affordable when compared to data warehouses. The data warehouse stores structured and processed data.
Although it requires more time and money, however once done, it is convenient for analysis to draw key insights and complex information.
6. Different Users
Now that we have established that the purpose of the data lake and data warehouse is different. It is important to see how and why the users of these two data technologies are different from each other.
A data lake stores data in a raw and pre-processed format which is why it requires data scientists to draw insights and other important information. Data warehouse, on the contrary, is used by business analysts to create visual reports and charts.
Data Lake vs Data Warehouse: Which One Is The Best Fit For Your Organization?
In this tug of war between data warehouse vs data lake, it depends on the size of the organization and the amount of data and storage requirements companies have.
Most organizations use a combination of a data lake and a data warehouse as it suits their needs of storing, managing, and analyzing data. The blend of a data lake and data warehouse is an ideal setup for all companies as it provides them with a holistic storage solution.
Conclusion
We have reached the conclusion of data warehouse vs data lake. We hope you have got a detailed view of the concepts of data warehouse, data warehouse benefits, data lake concepts, and benefits of the data lake.
As stated earlier, it depends on the nature of the company and its data storage capabilities and which of the two would be best for it.
We would like to believe that this blog must have answered your questions and if not, let us know your doubts in the comments section below.





